Monitoring Linux Servers with Prometheus and Grafana: A Production Setup Guide
A complete, production-oriented walkthrough of standing up Prometheus, Grafana, and node_exporter across a fleet of Linux servers — with dashboards, alerting, and high availability.
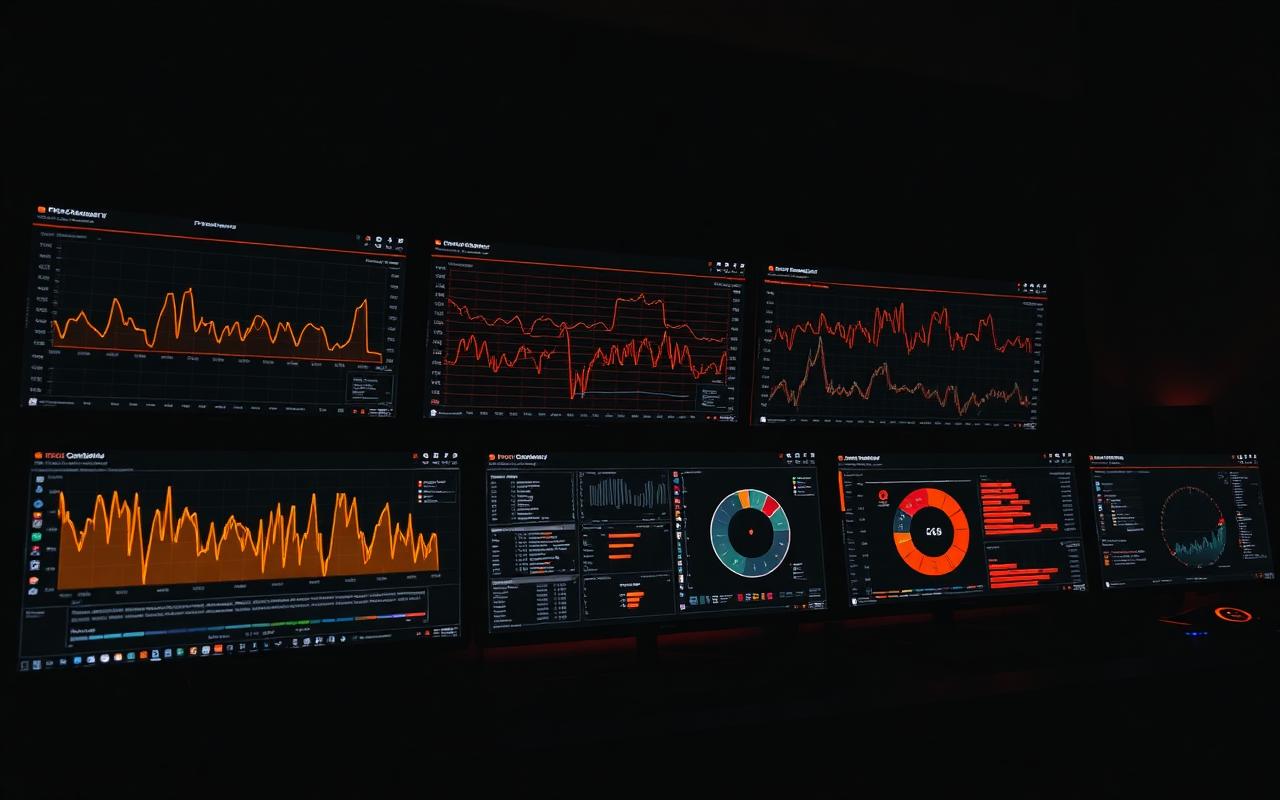
Why Prometheus + Grafana
Prometheus and Grafana have become the de facto open-source observability stack for Linux infrastructure. Prometheus scrapes metrics from instrumented targets, stores them as a time series database, and evaluates alerting rules. Grafana visualizes those metrics through dashboards. Together they cover the metrics half of observability comfortably.
Architecture for production
For a small fleet (under fifty servers), a single Prometheus instance is fine. For larger fleets, run Prometheus in HA pairs with identical configuration scraping the same targets, deduplicated at query time by Thanos or VictoriaMetrics. Long-term metric retention is best handled by an object-storage-backed tier (Thanos, Mimir, VictoriaMetrics) because raw Prometheus retention is constrained by local disk.
Installing Prometheus and node_exporter
Download the official binaries for Prometheus and node_exporter (do not use distribution packages — they are usually outdated). Run them under systemd unit files with a dedicated service user and a restricted home directory. node_exporter binds to a TCP port (default 9100); restrict access via firewall or a reverse proxy with mTLS.
Configuring scrape targets
For static fleets, the file_sd_configs discovery mechanism reads a JSON file listing targets — easy to maintain through configuration management. For cloud fleets, use the AWS, Azure, or GCE service discovery mechanisms to pick up instances automatically. Tag instances by environment, role, and team so dashboards and alerts can filter accordingly.
Dashboards that engineers actually use
Start with the Grafana Labs official node_exporter full dashboard (ID 1860) as a baseline, then customize. Build per-team dashboards focused on the services that team owns rather than universal host-level dashboards. The fastest path to dashboards being ignored is too many panels showing aggregated infrastructure that no one is responsible for.
Alerting that doesn't burn out the on-call
Define alerts against SLOs and burn-rate budgets, not against raw thresholds. CPU at 90% is not an incident; checkout error rate above 1% for ten minutes is. Page only on actionable conditions; route everything else to a ticket queue. Run quarterly alert reviews and delete alerts that have fired and been ignored more than three times.
Operating at scale
Federate Prometheus instances by region or by team rather than running one giant central instance. Use recording rules to precompute expensive queries. Cap label cardinality — high-cardinality labels (user IDs, request IDs) blow up time series storage.
Reader questions, answered
Should we use Loki for logs too?+
If you are already invested in Grafana, Loki is the path of least resistance. Otherwise OpenSearch or a hosted log platform may serve you better.

Raza Ahmad is a technology author and IT infrastructure specialist based in Melbourne, Australia. He writes practitioner-grade guides on cloud computing (Azure and AWS), cybersecurity, enterprise networking with Cisco platforms, Linux administration, DevOps, and virtualization. His work focuses on translating complex infrastructure topics into clear, accurate guidance that engineers, system administrators, and IT decision makers can put to work in production environments. Every article published under his byline is fact-checked against current vendor documentation, official standards, and Raza's own hands-on experience operating the technologies he covers.
More from Programming & Development

The Kubernetes Production Readiness Checklist Engineers Actually Use
A practitioner's checklist for taking a Kubernetes cluster from “it works on my laptop” to “I am happy to be on call for this.”
Terraform vs Pulumi: Which Infrastructure-as-Code Tool Should You Choose?
A working engineer's comparison of the two leading IaC platforms based on real deployments at scale.
The Complete Linux Administration Guide for Production Servers
A working systems administrator's reference for installing, hardening, monitoring, and troubleshooting Linux servers in real production environments.
One email. The technology stories that actually matter for engineers.
A curated digest of the week's most useful tutorials, reviews, and analysis — no clickbait, no AI summaries of someone else's work.
Free. Unsubscribe anytime. See our privacy policy.